I'll probably turn this into a series of posts, but for now, I'll just demonstrate the basics of the SysOperation framework.
The
SysOperation Framework, initially called Business Operation Framework, seem to be the new substitute of the RunBase framework. As such, it allows you to perform operations that require parameters from the user, it allows you to set the operations to be executed in batch, or in a new asynchronous way, or in a synchronous manner. The great thing is that it simplifies the pack / unpack of variables that was pretty nasty in the RunBase framework, taking advantage of the Attributes feature, introduced with AX 2012.
So to get started, we must understand that the SysOperation framework works in a way that's close to the Model-View-Controller (MVC) pattern.
The key objects here are:
- Data Contract:
The data contract is the model class in which we define which attributes we need for our operation, commonly set as parameters by the user in a dialog. It's nothing more than a model class with a few attributes in it. We can define a SysOperation Data Contract class simply by adding the DataContractAttribute attribute to its declaraion. Additionally, if we want a set of methods to be available to us, we can also extend the SysOperationDataContractBase base class. With this class, we can define how our basic dialog will look like to the user. We can define labels, groups, sizes and types of the parameters.
- UI Builder:
The UI builder class is actually an optional class for the SysOperation framework, which kind of acts as the view part of the pattern. You should only use it if you want to add some extra behavior to the dialog that AX constructs dynamically for you. If you are perfectly happy with the dialog AX shows you when you run your operation, you shouldn't worry about this class. To create a UI Builder, you should extend the SysOperationAutomaticUIBuilder class. It will provide you a set of methods to work with the dialog's design, but we usually add extra behavior or customize a lookup inside the postBuild method.
- Controller:
The controller class has greater responsibility than the others. As the name suggests, it is the class that orchestrates the whole operation. The controller class also holds information about the operation, such as if it should show a progress form, if it should show the dialog, and its execution mode - asynchronous or not. To create a controller class you should extend the SysOperationServiceController, which will give you all of the methods you need.
- Service:
There are some who put the business logic on controller classes so that they also perform the operation itself. I'm particularly not a big fan of that, it's too much responsibility for a single class! The programmers who created the SysOperation framework probably think the same, and they have made a way to separate the operation. You can create a service class! The only thing you have to do is extend the SysOperationServiceBase class and you're good to go. This class is the one that should contain all the business logic. When constructing your controller, you will indicate which class holds the operation that the controller will trigger, I'll demonstrate it later.
So this was a brief explanation in my own words of how the SysOperation currently works. For more information, you can also download the official Microsoft whitepaper
here.
Now on to the code.
SysOperating it
To define our Model, or our DataContract, all we have to do is create a class, with each of the values created as the class' fields, and parm methods, which will be our "properties". Each field that we want to
pack and
unpack during the execution of the operation has to have its parm method decorated with the
DataMemberAttribute attribute. If we don't add that attribute, the value for that field won't be packed to the server, and will not be initialized when you try to access it on the service class. Additionally, parm methods without the attribute will not have its field displayed on the default dialog.
So for example, consider the following model class:
[DataContractAttribute]
class SysOperationDemoDataContract
{
Name name;
BirthDate birthDate;
MonthsOfYear monthThatWontBeSerialized;
}
[DataMemberAttribute]
public BirthDate parmBirthDate(BirthDate _birthDate = birthDate)
{
birthDate = _birthDate;
return birthDate;
}
[DataMemberAttribute]
public Name parmName(Name _name = name)
{
name = _name;
return name;
}
public MonthsOfYear parmMonthThatWontBeSerialized(MonthsOfYear _monthThatWontBeSerialized = monthThatWontBeSerialized)
{
monthThatWontBeSerialized = _monthThatWontBeSerialized;
return monthThatWontBeSerialized;
}
When we run a Controller that uses the above class as a DataContract, the following dialog is automatically constructed, without the fields that do not have the DataMemberAttribute. As you can see, our field
monthThatWontBeSerialized wasn't even added to the dialog:
So after easily defining our model, which is a class that will store all of the values that we will need from the user - or not - for our operation, we can define our service.
To define our service class and have it called by the SysOperation framework, we
must define a method that receives our data contract as a parameter. So for this demo, I have defined the following class:
class SysOperationDemoService extends SysOperationServiceBase
{
}
public str performDemo(SysOperationDemoDataContract _contract)
{
str info = strFmt('%1 was born in %2', _contract.parmName(), _contract.parmBirthDate());
info(info);
return info;
}
It doesn't do much. It takes what the user has typed in the dialog and displays it on the Infolog. In a real scenario, this class could either contain the business logic itself, or just interact with other classes that contain it. I personally rather have the business logic in other classes, because by pattern, this class should always have the "Service" suffix. I'll talk more about naming conventions for the SysOperation later.
So we have our Model, we have our service. What about our controller?
The controller class has a few key methods like the RunBase framework, that you should be very familiar with, which are:
- main
- construct
- new
- validate
- run
Their names are self explanatory, and if you are a little familiar with the RunBase framework you'll have no problem getting over them. I put the
new method in that list because the
new method of the base SysOperationServiceController class receives two strings as parameters, which are the name of the class and the method of the service to be executed. There is a neat method called
initializeFromArgs which sets these values on the controller after it's constructed, given a correctly intialized
Args object. This method allows you to use it with menu items, I'll blog about it later. Anyway, for this example we'll override the new method on our controller.
I've also put the construct method on the list. As a general good practice, your controller should have a public static method called
construct, which will do all the dirty constructing (duuh) work. Additionally, you can override the
new method and set it as a protected method, so that anyone who wants to use your controller will have to call the
construct method.
So here's how I'll define our sample controller:
class SysOperationDemoController extends SysOperationServiceController
{
}
protected void new()
{
// This tells the controller what method it should execute as the service. In this case, we'll run SysOperationDemoService.performDemo()
super(classStr(SysOperationDemoService), methodStr(SysOperationDemoService, performDemo), SysOperationExecutionMode::Synchronous);
}
public static SysOperationDemoController construct()
{
SysOperationDemoController controller;
controller = new SysOperationDemoController();
controller.parmShowDialog(true); // Actually the default value
controller.parmShowProgressForm(false);
return controller;
}
public static void main(Args _args)
{
SysOperationDemoController controller;
controller = SysOperationDemoController::construct();
controller.startOperation();
}
protected boolean validate()
{
SysOperationDemoDataContract contract;
boolean ret = true;
contract = this.getDataContractObject();
if (contract.parmBirthDate() > DateTimeUtil::date(DateTimeUtil::addYears(DateTimeUtil::utcNow(), -18)))
{
// Failing the validate will not close the dialog, and the user will have another chance of inputting the correct values
ret = checkFailed('The user is underage!');
}
return ret;
}
public void run()
{
info('Run method has been called');
super();
}
protected ClassDescription defaultCaption()
{
// This will be the dialog's caption
return 'SysOperation demo';
}
So as you can see we define which method will be executed as the service on the
new method.
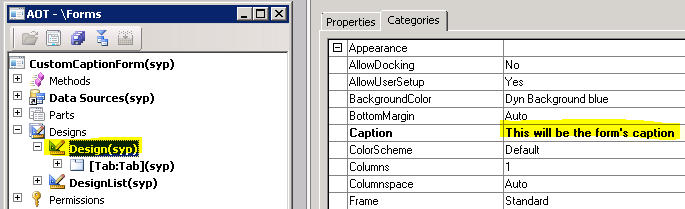
The construct method does the dirty work, setting some properties on the controller. The validate then checks if the user is at least 18 years old. If the validate fails, the user has another chance of setting the correct values on the dialog. Also, as a tip, I've set the dialog's caption by overriding the
defaultCaption method. As for the
run method, I've only overwritten it so that you can see the execution flow, which is:
>> main
>> construct
>> validate
>> run
Draw a sequence diagram in your head. :)
With the three classes that I have described here, you can actually run a simple SysOperation framework demo. You can do this by simply opening the controller class and pressing F5.
Here's some tips that can save you some time:
- You should generate incremental IL for every change on any of the classes from the SysOperation framework. It won't take long, and unfortunately, it's necessary
- When you start getting odd behaviors, specially when you change something on your DataContract and it doesn't reflect on your dialog, you should clean the usage cache. You can do this by clicking on Tools > Options > Usage data > Reset
- You can debug SysOperation services if your Controller class' execution mode is either Synchronous or Asynchronous, when you've unchecked the option to execute business operations in CIL. You can get more info on executing business operations in CIL here.
As I've mentioned, the UI Builder class allows us to completely customize the dialog which is constructed for us. Since I'll probably turn this into a series of posts, I'll demonstrate this over the next posts.
Even though it's fairly easy and simple to understand, I must confess that I think it requires too much code infrastructure to perform some simple tasks. It feels strange having to write at least 3 classes to perform a simple delete operation that requires some extra logic or validation, for example. Still, I'd rather have to do so instead of having to control the dirty pack / unpack pattern of the RunBase framework.